Acteurs du Web04:18
La particularité du Web est qu'elle réside sur une architecture client-serveur.
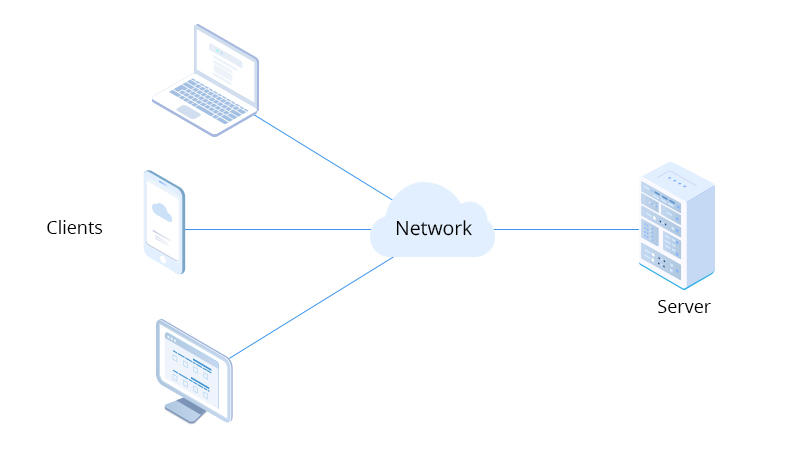
Ceci requiert une connectivité permanente mais donne également énormément de possibilités.
Par exemple, ChatGPT requiert une puissance de calcul gigantesque (258 000 cores de processeurs pour GPT-3) mais est accessible via n'importe quel ordinateur ou smartphone.

Le client04:18
Le serveur04:18

Definition (Serveur)
Le serveur est un programme qui écoute sur le réseau et qui répond aux requêtes HTTP des clients.
Analogie douteuse: cuisiniers du McDonalds
Le protocole HTTP04:18
Definition
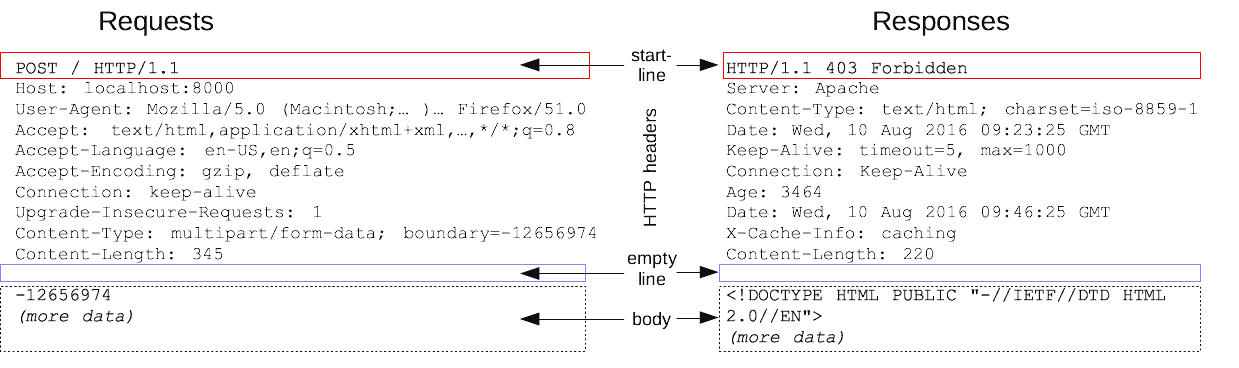
Le protocole HTTP est le standard qui dictent comment serveurs et clients communiquent.
Clients et serveurs communiquent par message structuré (première ligne, l'en-tête, corps).
Méthodes HTTP04:18
Codes Réponse04:18
Requêtes GET04:18
Requêtes POST04:18
Stateless04:18

Le protocole HTTP est comme Dory, il oublie les requêtes des clients dès qu'il les a traitées.
Remark
Le protocole HTTP est stateless: les requêtes sont traitées indépendemment des requêtes précédentes et les communications sont coupées dès qu'elles sont terminées.
Le client doit rappeler à chaque requête qui il est via ce qu'on appelle des cookies (dans quelques slides)
Cookies04:18
L'idée des cookie est que le client rappelle au serveur qui il est à chaque requête parce que le serveur a oublié (une promenade en mer, une promenade en mer).
Definition (Cookie)
Un cookie est un bloc de données créé par le serveur et utilisé pour les requêtes suivantes jusqu'à son expiration.

Cookies: diagramme de séquence04:18
Cookies: Authentification04:18
Cookies: Tracking04:18
Cryptographie asymétrique04:18
La sécurité du Web fonctionne sur la cryptographie asymétrique.

- Deux clés inverses l'une de l'autre: un message crypté avec l'un peut être déchiffré avec l'autre.
- Objectifs:
- Confidentialité
- Authentification de l'expéditeur
- Le nom public/privé vient de si cette clé est partagée ou non.
HTTPS04:18
Différentes architectures04:18
Sites statiques04:18
Applications04:18
SPA vs MPA04:18
Avantages des SPA04:18
Client-Side Routing04:18
Kim Kardashian04:18
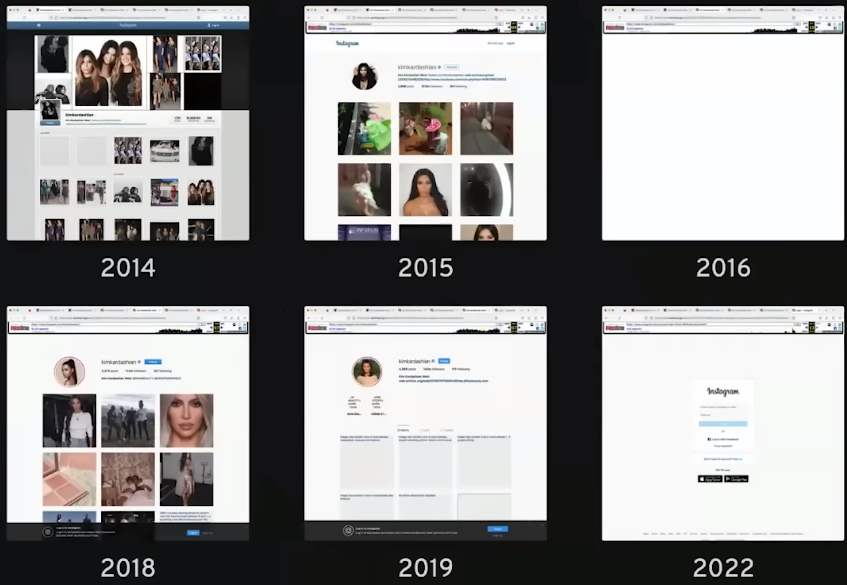
Question
Que s'est-il passé en 2016?
Fonctionnement d'une MPA04:18
Fonctionnement d'une SPA04:18
MPA vs SPA04:18
Le SSR04:18
SSR: fonctionnement04:18
Hydration04:18
Chaque fois qu'on résoud un problème en frontend, on en crée un nouveau. Le SSR crée le problème de l'hydration, une période durant laquelle la page est affichée mais pas interactive.

Ce problème n'est pas encore résolu de manière satisfaisante, bien qu'il existe des projets prometteurs tels que Qwik ou Astro